
Why System Integration Fails at Scale — And What Technology Leaders Must Rethink
System integration rarely collapses because systems refuse to connect. In fact, most large-scale integrations appear successful at first. Interfaces communicate. Data moves across environments. Performance dashboards remain within acceptable ranges. Stakeholders approve deployment.
And then, slowly, instability begins to surface.
In my experience working at the intersection of artificial intelligence products and enterprise infrastructure, integration fails not because of connectivity gaps but because of resilience gaps. Systems are validated in controlled settings, yet production environments behave very differently. Real systems experience fluctuating traffic, evolving dependencies, shifting configurations, and operational stress that is rarely predictable.
The difference between connected and resilient becomes visible only at scale.
As artificial intelligence systems become embedded into enterprise workflows, the complexity multiplies. AI models do not operate in isolation. They depend on multiple interconnected layers, including:
• Telemetry ingestion pipelines
• Distributed compute environments
• Data synchronization layers
• Network stability
• Cloud orchestration systems
• Security governance frameworks
When these layers interact under real operational conditions, small weaknesses amplify. A minor instability in telemetry can degrade model outputs. A subtle compute imbalance can delay inference cycles. A configuration drift in orchestration can cascade across dependent services.
Often, what appears to be an AI failure is actually an integration resilience failure.
One recurring pattern I observed is that integration testing tends to rely on static assumptions. Systems are tested against predefined load patterns and limited disruption scenarios. These tests confirm that the system functions. They do not always confirm that systems endure.
Traditional stress evaluation frequently uses uniform or randomized disruption. While this can reveal obvious weaknesses, it does not necessarily reflect how systems behave when operational priorities conflict. Every enterprise environment operates with intent. Some systems must prioritize availability. Others must preserve strict security thresholds. Some can tolerate latency while others cannot.
Without explicitly defining this architectural intent, validation remains generic rather than contextual.
This realization shaped much of my work in resilience modeling and led to my role as a named inventor on United States Patent Number 12,242,370 B2. The patent introduces an intent-based methodology for variably testing digital environments. Instead of injecting arbitrary disruption, the approach calibrates variability according to system sensitivity and operational thresholds.
The core idea is straightforward. Resilience must reflect purpose.
System integration fails at scale because organizations often validate connectivity without validating continuity. They confirm that systems exchange information but do not sufficiently examine how those systems sustain intelligent workloads under evolving conditions.
Technology leaders must rethink integration as a strategic discipline rather than a deployment checkpoint.
Several shifts are necessary.
- First, integration must be treated as an ongoing lifecycle. Artificial intelligence systems continuously evolve. Data volumes change. New services integrate with existing architectures. Without continuous evaluation, small misalignments compound into structural fragility.
- Second, architectural priorities must be defined early and clearly. Leaders should ask:
- Which services are non-negotiable under stress
- Where can degradation occur safely
- What operational thresholds define acceptable performance
- Which components introduce cascading risk
Clarity at this stage informs how systems should be evaluated.
- Third, stress evaluation must incorporate contextual awareness. Context-aware testing aligns system variability with business-critical priorities. This approach provides insight into how environments behave when operational conditions shift. Especially in AI-driven systems, where outputs influence monitoring, automation, and decision making, stability is inseparable from trust.
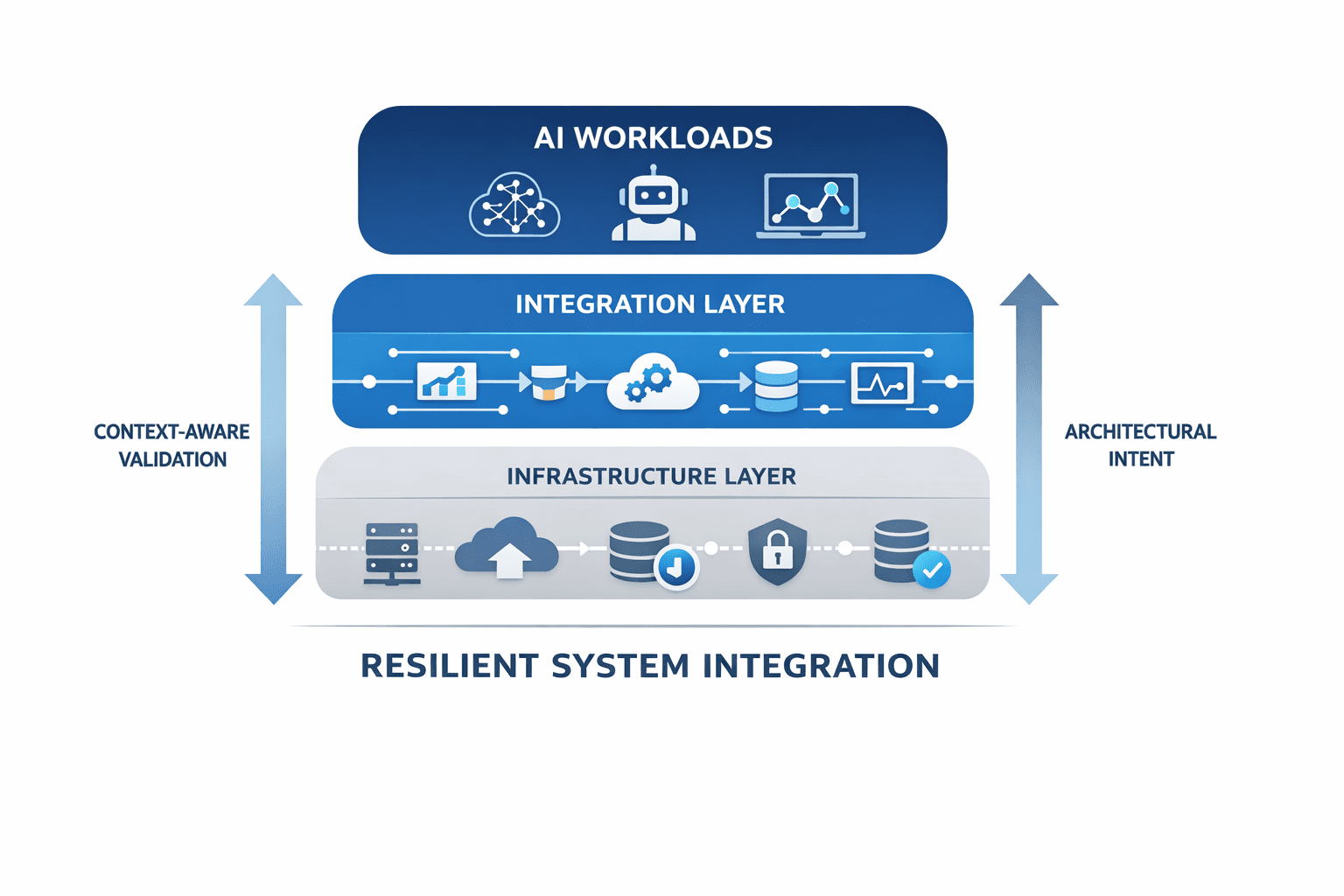
If any upstream component drifts, downstream intelligence degrades. As organizations embed AI deeper into operations, tolerance for unpredictability declines. Integration resilience becomes foundational to enterprise continuity.
From a product management perspective, integration resilience is not peripheral. Product leaders define system intent. They articulate expected behavior under real-world conditions. That intent must guide architectural decisions and validation frameworks.
Integration should not be reduced to technical plumbing. It is an expression of strategic alignment between product expectations, infrastructure constraints, and governance requirements.
At scale, system integration fails not because technology leaders lack expertise but because resilience is often assumed rather than engineered deliberately. As digital ecosystems expand and artificial intelligence becomes operationally embedded, that assumption grows riskier.
The next phase of enterprise transformation will not be defined by how quickly systems connect but by how reliably they sustain intelligent workloads under dynamic conditions.
Integration must evolve into a discipline grounded in contextual validation, clear intent definition, and cross-functional alignment.
Only then can scale become stable rather than fragile.

About SAYALI PATIL
Sayali Patil is a Product Manager and AI-driven network automation specialist with experience building enterprise-scale platforms.